
26 de novembro de 2025



Lançamento do PostgreSQL 11
14 de novembro de 2018
IBM Confia no Kubernetes para Estratégia Avançada de Análise
12 de dezembro de 2018Definindo Cache:
Na área da computação, cache é um dispositivo de acesso rápido, interno a um sistema, que serve de intermediário entre um operador de um processo e o dispositivo de armazenamento ao qual esse operador acessa. A principal vantagem na utilização de um cache consiste em evitar o acesso ao dispositivo de armazenamento, que pode ser demorado, armazenando os dados em meios de acesso mais rápidos como a memória RAM.
Com os avanços tecnológicos, vários tipos de cache foram desenvolvidos. Atualmente há cache em processadores, discos rígidos, sistemas, servidores, nas placas-mãe, clusters de bancos de dados, entre outros. Qualquer dispositivo que requeira do usuário uma solicitação/requisição a algum outro recurso, seja de rede ou local, interno ou externo a essa rede, pode requerer ou possuir de fábrica o recurso de cache.
Contextos onde se pode notar vantagem em utilização de cache:
– Nos casos dos processadores, em que cache disponibiliza alguns dados já requisitados e outros a processar;
– No caso dos navegadores web, em que as páginas são guardadas localmente para evitar consultas constantes à rede (especialmente úteis quando se navega por páginas estáticas);
– No caso das redes de computadores, o acesso externo, ou à Internet, se dá por meio de um software que compartilha a conexão ou link, software este também chamado de proxy, que tem por função rotear as requisições a IPs externos à rede que se encontra. Os proxys têm capacidade de caching: ao armazenar o conteúdo de páginas web já visitadas pelos usuários da rede na qual faz parte e fornecer esse conteúdo às novas requisições, minimizam o consumo do de largura de banda e agilizam a navegação;
– Os servidores web também podem dispor caches configurados pelo administrador, que variam de tamanho conforme o número de page views que o servidor tem.
Como funciona um servidor de cache?
Para ilustrar melhor o como é o mecanismo de funcionamento de um servidor de cache, imagine que você está acessando uma página de um e-commerce. O navegador vai pedir uma página que exiba toda a lista de produtos e preços e para isso o servidor web terá que fazer toda a conexão com banco de dados, aguardar os servidores, transformar em html para então reenviar a informação para o navegador. Com o cache, ao “devolver” o html para o navegador, o servidor cria um arquivo com esse html, fazendo com que esse tempo de processamento – e consequentemente o seu site – seja mais rápido.
Uma coisa interessante de se observar é o fato de que muitas vezes o site possui partes comuns a várias páginas, como o estilo (fonte, fundo de tela, cores, bullets, logos, símbolos, etc). Quando isso ocorre, o navegador tem a oportunidade de aproveitar esses pedaços no carregamento da página, mesmo quando o usuário visita uma página nova.
Os servidores de cache mais conhecidos são os Proxys e DNS. Os Proxys funcionam conforme exemplificamos: recebem pedidos de acesso as páginas web, devolvem aos utilizadores e guardam para que quando outro utilizador voltar a pedir a mesma, o acesso seja mais rápido; já os DNS, além de guardar os vários pedidos que recebem, podem também resolver nomes.
Um servidor web bem configurado é hábil portanto a acelerar o processo de cache dos navegadores e traz benefícios para o usuário e para o provedor, seja em acesso mais rápido e menor consumo de banda (para o usuário) como menor consumo de banda além e usuários/clientes mais satisfeitos (por parte do servidor).
Data Grid
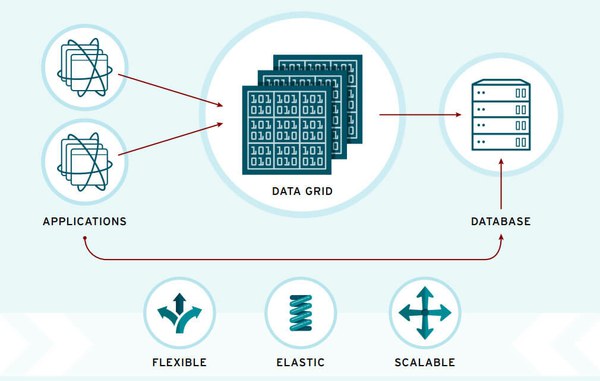
Imagem 1: Exemplo de uso para o Data Grid.
Um data grid em memória é um sistema de gerenciamento de dados distribuído para dados de aplicativos que:
– Utiliza memória RAM para armazenar informações e assim oferecer um tempo de resposta mais rápido, de baixa latência e com rendimento bastante elevado;
– Mantém cópias de informações sincronizadas entre diferentes servidores, a fim de oferecer disponibilidade contínua, confiabilidade nas informações e escalabilidade linear;
– Pode ser usado como cache distribuído, banco de dados NoSQL e broker de eventos.
As vantagens técnicas de um data grid em memória (IMDG) oferecem vários benefícios às empresas. Entre eles, decisões mais rápidas, maior produtividade e experiência e interação aprimorada com clientes.
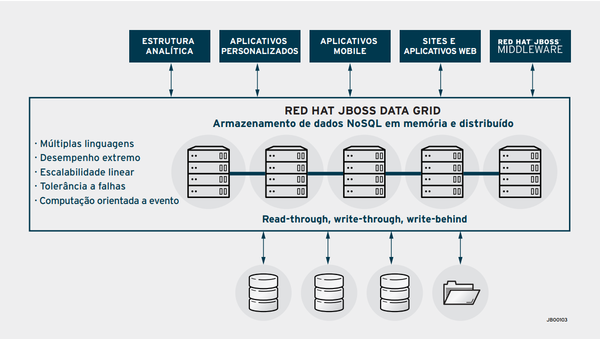
Imagem 2: Visão geral do JBoss Data Grid. Fonte https://www.redhat.com
Um dos casos de uso mais comuns para o uso de servidores de data grid como o Red Hat JBoss Data Grid, são implantados como um armazenamento rápido em memória para os dados frequentemente mais acessados nas aplicações. Como uma variação do cache de dados, os data grids são frequentemente utilizados para armazenar dados transitórios em aplicações de e-commerce, como, por exemplo, sessões web e dados de carrinho de compras. Como resultado, essas aplicações apresentam melhor desempenho e escalabilidade. Além disso, essas aplicações acessam sistemas de gerenciamento de bancos de dados (DBMS) e sistemas de backend transacional com menos frequência, resultando em custos operacionais reduzidos nesses sistemas.
Data grid são adequados para lidar com os três V’s de big data: velocidade, variabilidade e volume. Para oferecer suporte às necessidades de velocidade de big data, os servidores de data grid oferecem suporte a centenas de milhares de atualizações de dados em memória por segundo. Data grid oferece suporte à variabilidade de big data de maneira semelhante aos armazenamentos de dados NoSQL. Por fim, servidores de data grid podem ser utilizados em cluster e escalados para suportar grandes volumes de dados. Os dispositivos de IoT (Internet das Coisas) geram volumes massivos de dados, quase sempre em intervalos frequentes. O JBoss Data Grid fornece armazenamento de dezenas de terabytes de dados, com tempo de resposta mais rápido e análise praticamente instantânea. Como resultado, os dados de IoT (Internet das Coisas) podem ser processados praticamente na mesma velocidade em que são gerados.
Fonte:



{kind=link}
{kind=link}
{kind=link}